【WEB开发】HTML 探秘:零基础玩转网页结构
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
为什么“标记”才是网页的灵魂?我们每天在浏览器中看到的五彩斑斓、功能各异的网页——新闻门户、社交平台、在线商店、视频网站……它们的外表可能千差万别,但追根溯源,它们都建立在一个共同的基础之上,那就是 HTML。 HTML 的全称是 HyperText Markup Language,中文译为“超文本标记语言”。让我们拆解一下这个名字:
所以,HTML 的核心作用就是定义网页的内容与结构 。它像建筑的蓝图和骨架,规定了哪里是标题,哪里是段落,哪里放图片,哪里是导航栏。网页上你看到的所有文字、图片、按钮、表格,都是通过 HTML 标记赋予其身份和位置的。 为什么说“标记”是网页的灵魂呢?因为正是这些看似简单的标记,赋予了原始数据以语义 (semantics) 。一个 一、最小 HTML 文档一个功能完整、能被浏览器正确识别和显示的 HTML 页面,最少只需要寥寥数行代码。下面就是一个符合现代 HTML5 标准的最小文档结构示例 : 就是这短短的几行代码 (如果算上
|
<head> | <title><meta>, <link>, <style>, <script> | <title>在标签栏外) | |
<body> | <h1>-<h6>, <p>, <a>, <img>, <ul>, <ol>, 表单, 视频等 |
<h1> – <h6>我们在写文章或者做笔记时,会使用不同大小的标题来组织内容,使其更有条理。HTML 中的标题标签也是为此而生。
HTML 提供了六个级别的标题标签,从<h1>到<h6>,用于定义内容的标题层级。
<h1>代表最高级别的标题,通常用于整个页面的主标题,表明页面的核心主题。一个 HTML 页面通常应该只包含一个 <h1> 标签。
<h2> 代表次级标题,用于划分主要章节。
<h3> 到 <h6> 则代表更低级别的子标题,重要性依次递减。
结构化内容: 标题标签清晰地勾勒出文档的结构和脉络,帮助用户快速理解内容的组织方式,提升可读性。
搜索引擎优化 (SEO): 搜索引擎(如百度、谷歌)会分析页面中的标题标签,特别是
<h1>和<h2>,来判断页面的主要内容和关键词,这对于网站的搜索排名有积极影响。
可访问性: 对于使用屏幕阅读器的用户(例如视障人士),他们可以借助标题在页面中快速导航,跳转到感兴趣的部分,就像我们通过目录查找书本内容一样。
<p>段落是构成文章和网页内容的基本单位。
<p>标签用于表示一个文本段落。它会将一段相关的文字组织在一起,形成一个逻辑单元。
<p>标签是一个块级元素。这意味着它在浏览器中显示时,通常会自己占据一整行的宽度,并且会在其前后自动产生一些垂直的空白间距,从而与其他内容(如其他段落或标题)分隔开。
<a>链接是超文本的核心,它使得网页能够相互连接,形成网络。
<a>标签(也称为锚点元素)用于创建超链接。通过链接,用户可以从当前页面跳转到:
核心属性:
href : 这是<a>标签最重要也是必需的属性,它指定了链接的目标 URL (统一资源定位符,即网址)。
绝对 URL: 指向互联网上某个资源的完整地址,通常以 http:// 或 https:// 开头。例如:<a href="https://www.mozilla.org/zh-CN/">访问 MDN</a>。
相对 URL: 指向同一网站内部的其他页面或资源,其路径是相对于当前页面的。
target: 这个属性定义了在何处打开链接的文档。
target="_self": (默认值) 在当前浏览器窗口或标签页中打开链接。
target="_blank": 在新的浏览器窗口或标签页中打开链接。这在链接到外部网站时非常常用,可以避免用户离开当前站点。
链接文本: 放置在<a>和</a>标签之间的内容,就是用户在页面上看到的、可以点击的链接文本或图片。链接文本应该清晰地描述链接指向的内容。
示例:
<p>想学习更多关于 Web 开发的知识吗?可以访问 <a href="https://developer.mozilla.org/zh-CN/" target="_blank">MDN Web Docs</a>。</p>
<p>如果你想回顾本页的 <a href="#section1">第一节内容</a>,请点击这里。(假设页面前面有 `<h2 id="section1">第一节</h2>`)</p>
<p>有任何问题,欢迎 <a href="mailto:contact@example.com">给我们发送邮件</a>。</p>
正确使用链接标签,并为其提供有意义的href属性和描述性的链接文本,是构建用户友好且功能强大的网页的关键。
<ul>, <ol>, <li>HTML 提供了两种主要的列表类型,用于组织和显示项目集合。
无序列表 <ul> :
用于表示一组项目,这些项目之间的顺序不重要。
浏览器通常会在每个列表项前面显示一个项目符号 ,如小圆点、小方块或小圆圈。
适用场景: 购物清单、功能点罗列、导航菜单中的链接等。
有序列表 <ol>:
用于表示一组项目,这些项目之间的顺序非常重要。
浏览器通常会在每个列表项前面显示一个编号,如数字 (1, 2, 3...) 或字母 (A, B, C...; a, b, c...; i, ii, iii...)。
适用场景: 操作步骤指南、排行榜、食谱配方、法律条款等。
常用属性:
type="1": 数字 (默认值)type="A": 大写字母type="a": 小写字母type="I": 大写罗马数字type="i": 小写罗马数字type: 可以改变<ol>列表的编号样式。
start: 可以指定列表从哪个数字或字母开始计数。例如start="3"会让列表从 3 (或 C, c, III, iii) 开始。
reversed: 一个布尔属性,如果设置了,列表项会降序排列。
列表项 <li>:
无论是<ul>还是<ol>,它们内部都必须包含一个或多个<li>标签。每个
<li>标签代表列表中的一个单独的项目。<li>是<ul>和<ol>的直接子元素。
嵌套列表:
<li>列表项内部再嵌套另一个<ul>或<ol>列表,从而创建出具有层级结构的子列表或多级列表。这对于组织复杂信息非常有用。示例:
<h4>我喜欢的水果 (无序列表):</h4>
<ul>
<li>苹果</li>
<li>香蕉</li>
<li>草莓
<ul><li>奶油草莓</li>
<li>巧克力草莓</li>
</ul>
</li>
<li>橙子</li>
</ul>
<h4>制作蛋糕的步骤 (有序列表):</h4>
<ol type="A" start="1"><li>准备材料:面粉、鸡蛋、糖、黄油。</li>
<li>混合面粉和糖。</li>
<li>加入鸡蛋和融化的黄油,搅拌均匀。
<ol type="i"><li>先慢速搅拌。</li>
<li>再快速搅拌至顺滑。</li>
</ol>
</li>
<li>倒入模具,放入预热好的烤箱。</li>
<li>烘烤30分钟。</li>
</ol>

<img><img>标签用于在 HTML 页面中嵌入一张图像。
<img> 标签是一个空元素,也叫自闭合元素。这意味着它没有结束标签 (比如不像 <p> 有 </p>)。在 HTML5 中,你可以简单地写成 <img...>,或者为了兼容 XHTML 的习惯写成 <img... /> (最后的斜杠是可选的)。
核心属性:
src: 这是<img>标签绝对必需的属性,它指定了要显示的图像文件的路径 (URL)。images/logo.png 或 ../icons/home.svg),也可以是绝对路径 (一个完整的网络地址,例如 https://www.example.com/path/to/image.jpg)。src 属性指定的图像无法找到或加载失败,浏览器通常会显示一个破碎的图片图标。alt: 这个属性提供了图像的替代文本描述。它非常非常重要,原因如下:alt属性中的文本。更重要的是,对于使用屏幕阅读器的视障用户,屏幕阅读器会朗读alt文本,让他们了解图像的内容。alt文本来理解图片的内容,这有助于图片被正确索引,并可能出现在图片搜索结果中。width 和 height: 这两个属性用于指定图像在页面上显示的宽度和高度,单位通常是像素 (px)。例如:<img src="photo.jpg" alt="风景照" width="600" height="400">。
即使图像文件本身还未完全加载完成,如果指定了width和height,浏览器就能提前知道图片将占据多大的空间,并为它预留位置。这样可以防止在图片加载过程中页面布局发生跳动或重排,提升用户体验。
最好指定与图片原始尺寸相符的 width 和 height,或者保持其宽高比,以避免图片被不成比例地拉伸或压缩而失真。
当我们用浏览器打开这个html文件时,浏览器究竟是如何理解这些用尖括号包围的文本,并最终在屏幕上呈现出图文并茂的网页呢?
这个过程大致可以分为以下几个主要阶段 :
一切始于数据。当浏览器请求一个 HTML 页面时(无论是从遥远的服务器通过网络下载,还是从你的本地电脑硬盘读取),它首先接收到的是一串原始的字节 (bytes)数据。
接下来,浏览器需要将这些原始字节转换成人类能够理解的字符 (characters)。这个转换过程依赖于文件所声明的字符编码,比如我们在<head>中设置的<meta charset="utf-8">。
拥有了字符流之后,浏览器内部的 HTML 解析器会开始进行“标记化”处理。这个过程有点像我们阅读英文句子时,会把一串字母分解成一个个独立的单词和标点符号。
解析器会逐个扫描字符,根据 HTML 的语法规则,将它们识别并组合成有意义的标记 (Tokens)。这些标记是构成 HTML 结构的基本单元,例如:
<html>, <p>, <img src="logo.png"></html>, </p>src, href, alt"logo.png", "https://example.com", "这是一个Logo"<p>你好</p> 中的“你好”一旦字符流被分解成一系列标记,解析器就会根据这些标记的含义和它们之间的关系,开始构建更高级的结构——节点。
每个 HTML 标签通常会转换成一个元素节点。例如,<p> 标签会变成一个 P 元素节点。
标签之间的文本内容会转换成文本节点。
HTML 注释会转换成注释节点。
每个节点对象都包含了关于原始 HTML 结构的所有信息,比如标签名、属性、以及它与其他节点的关系(如父节点、子节点等)。
这是至关重要的一步。由于 HTML 标签本身就具有嵌套结构(例如<body>
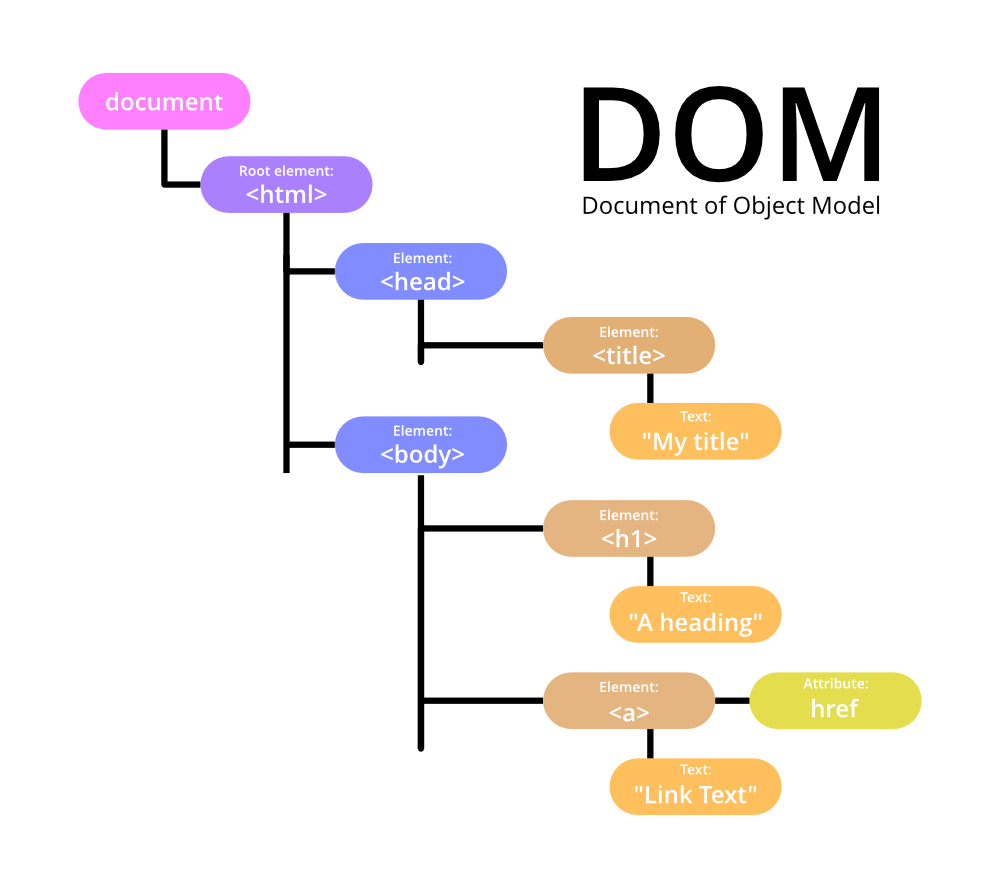
包含<p>,<p>又可能包含<a>),这些被创建出来的节点对象也会按照这种层级关系,被组织成一个树形结构。这个树形结构,就是大名鼎鼎的文档对象模型 (Document Object Model, DOM)。
DOM 树是 HTML 文档在计算机内存中的一种对象化、结构化的表示。它精确地反映了 HTML 文档的逻辑结构:
<html> 元素节点是整个 DOM 树的**根节点 (root node)**。
<head> 和 <body> 元素节点是 <html> 节点的**子节点 (child nodes)**。
<title> 和 <meta> 是 <head> 的子节点。
<h1>, <p>, <img> 等则是 <body> 的子节点或后代节点。
文本内容(文本节点)通常是元素节点的子节点,并且它们是树的叶子节点 (leaf nodes),因为文本节点自身不能再包含其他子节点。
可以把 DOM 树想象成一棵家族树:<html> 是最顶层的祖先,<head> 和 <body> 是它的孩子,以此类推,形成一个庞大的家族网络。
当浏览器辛辛苦苦构建好 DOM 树之后,它离把页面画出来还有一步之遥。因为 DOM 树只描述了页面的结构和内容,并没有包含样式信息(比如颜色、大小、位置等)。
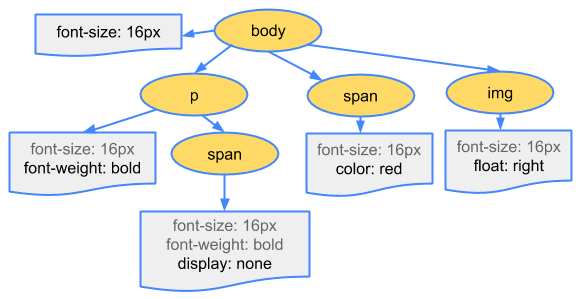
在构建 DOM 树的同时(或者紧随其后),浏览器也会解析页面中所有的 CSS 代码——无论是通过 <link> 标签引入的外部 CSS 文件,还是 <style> 标签内嵌的 CSS,亦或是元素上的 style 内联样式。解析 CSS 的结果是构建出另一个树形结构,称为 **CSS 对象模型 (CSS Object Model, CSSOM)**。CSSOM 包含了页面所有元素的样式规则。
接下来,浏览器会将DOM 树和CSSOM这两大模型结合起来,创建出渲染树,有时也被称为布局树 (Layout Tree)。
渲染树的一个关键特性是:它只包含那些最终需要在屏幕上实际显示出来的可见内容及其样式信息。
<head> 标签及其内部的所有内容(除了可能影响页面渲染的 <style> 等),是不会进入渲染树的。display: none;,那么它也不会出现在渲染树中。渲染树的存在是为了优化渲染性能。浏览器只需要关心那些真正需要绘制到屏幕上的元素,而忽略那些不可见的部分,从而节省了计算资源,提高了页面渲染的效率。
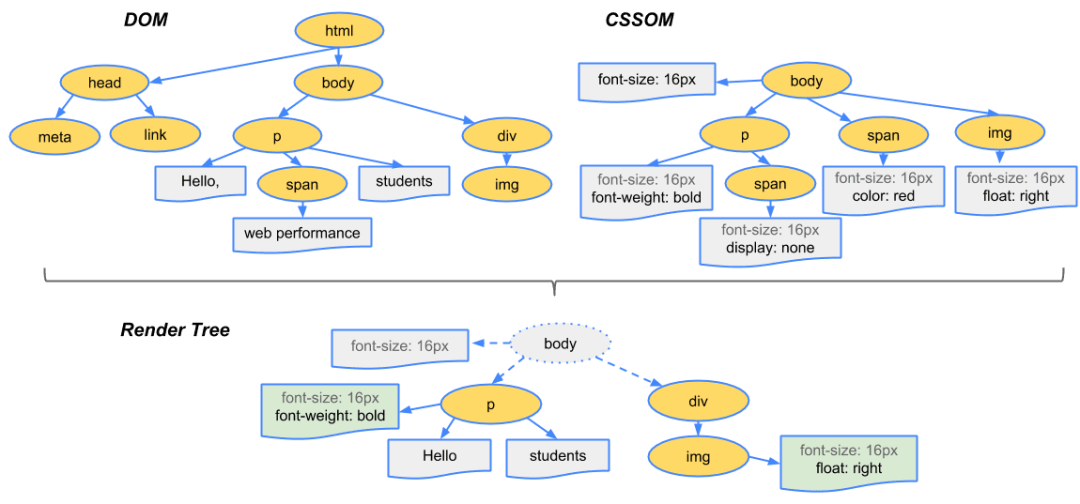
布局: 有了渲染树之后,浏览器会遍历渲染树,计算出每个可见元素在屏幕上的精确几何位置和大小。这个过程也称为“回流”或“重排”。浏览器会确定每个元素应该放在哪里,占据多大空间。
绘制: 布局完成后,浏览器的绘图引擎会根据渲染树中每个节点的样式信息(颜色、背景、边框、文本等)和计算好的几何信息,将它们实际绘制到屏幕的像素点上。这个过程可能涉及到将页面内容分成多个图层 (layers) 进行绘制,以优化性能。
最终,经过这一系列复杂的步骤,HTML 代码就神奇地变成了你在浏览器中看到的、可以交互的网页了。
阅读原文:原文链接






 400 186 1886
400 186 1886


