SQL数据库使用号段模式实现分布式ID
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
在单体系统时代,程序常被部署在单个物理机中,数据被存储在单个数据库中,我们可以采取数据库的自增 ID 来实现 ID 的全局唯一。 现在,系统开始从单体系统演变为分布式系统,当业务量和数据量增长之后,我们会选择分库分表。同时,随着微服务的推广与普及,我们的服务变得越来越多。 当然,在复杂的分布式系统中,我们同样需要对大量的数据进行唯一标识,而数据库的自增 ID 显然已经不能满足需求了。此时,我们就需要通过其他手段实现全局唯一 ID 了。 事实上,实现分布式全局唯一的 ID 有许多方案,包括基于 Redis 实现分布式 ID 方案、UUID、数据库号段模式、雪花算法等。但今天我们学习如何通过号段模式实现分布式 ID?为什么选择了“号段模式”。要回答这个问题,你需要先知道业务系统对分布式 ID 到底有要求? 在我看来,业务系统对分布式 ID 的要求,主要是 4 个包括:全局唯一性、趋势递增、单调递增和信息安全。接下来,我就和你一一分析下。 第一, 全局唯一性。确保 ID 的全局唯一性,是最基本的要求。 第二, 趋势递增。 趋势递增指的是,我们的分布式 ID 是呈增长趋势的,但是序列之间是不连续的。事实上,MySQL 的 InnoDB 引擎使用的是聚集索引,底层的数据结构是 B+ 树,使用有序的主键可以保证写入性能。 这也是为什么我们不提倡使用 UUID(Universally Unique Identifier,通用唯一识别码)作为 ID 的原因:UUID 的无序性,会导致新增数据的时候不是顺序的,从而出现频繁的页分裂,严重影响性能。 第三, 单调递增。我们要保证 ID 的增长不仅有序,而且还要单调递增,即下一个新增的 ID 一定大于上一个存在的 ID,从而保证能支持事务版本号、排序等场景。 第四, 信息安全 。 在一些应用场景下,我们需要 ID 有不规则性,确保它难以被猜测。例如,订单号,我们就需要确保它不是顺序递增的,不然,就很容易被竞争对手猜测出我们一天的订单量。 号段模式满足全局唯一性、趋势递增、单调递增三个要求,所以我选择了号段模式。而信息安全的要求,例如订单号场景,我们常常会采用雪花算法来实现。那么,如何通过号段模式实现分布式 ID? 使用号段模式如何实现分布式 ID?想一想,我们在数据库中创建一张全局 ID 序列表。例如,这张表叫做 common_sequence,它有 id、name、value、gmt_modified 四个字段。需要注意的是,每个业务用 name 字段来区分,每个 name 的 ID 获取是相互隔离、互不影响的。 当我们需要为某个表生成主键 ID 时,就从序列表中分配全局主键 ID。 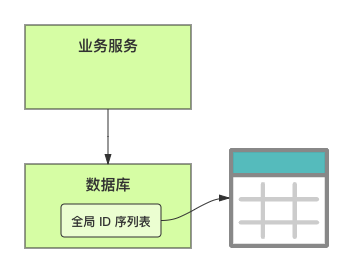 例如,我们新增一个客服工单,需要自增一个 ID。在这里,我们在全局 ID 序列表中,存入 name 等于 task 的记录,它的值是 1,也就是说,这个业务表的自增 ID 的当前值是 1。 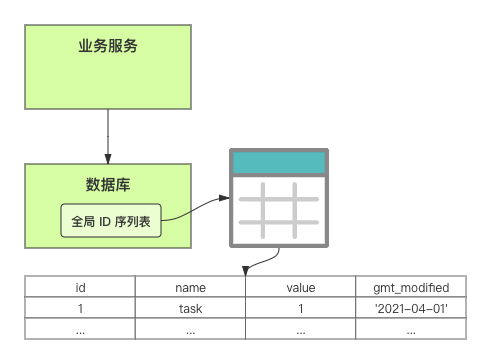 但是,如果我们每次获取 ID 都需要读写一次数据库,就会对数据库造成比较大的压力。那么,有什么比较好的优化方案呢? 事实上,我们可以做一个小优化:每次向全局 ID 序列表获取 一批 ID,然后存入 JVM 本地缓存中慢慢使用;当这批 ID 被消耗完了,再向全局 ID 序列表重新发起一次读写请求。这里,从全局 ID 序列表中申请的一批可用的 ID,我们称之为 ID 号段。 ID 分段之后,我们再来看看整体流程。 在新增客服工单时,我们会向全局 ID 序列表申请的可以使用的号段。假设,我们需要预申请 5000 个 ID。首先,客服工单服务会先查询全局 ID 序列表,获取当前 name 等于 task 的记录的最新值是多少。这里,最新值是 1。 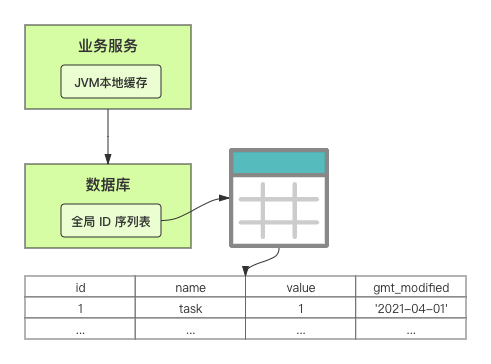 然后呢,全局 ID 序列表更新相对应的记录值。它把最新值 +5000,也就是 5001,存储起来。 紧接着,客服工单服务将可以使用的号段存储在 JVM 本地缓存中,即为[1, 5000]。客服工单服务在区间[1, 5000]中依次获取 ID。 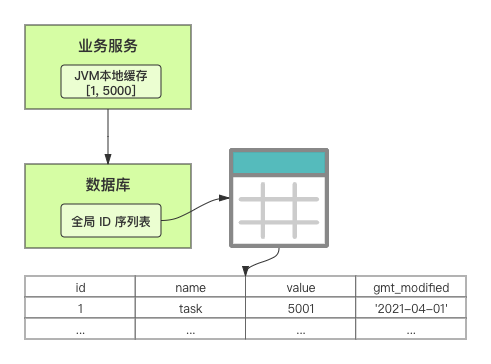 如果客服工单服务把区间的值用完了,再去请求全局 ID 序列表,获取到可以用的[5001, 10000]区间的 ID。 通过这个方案,我们用完号段之后再去数据库获取新的号段,可以大大减轻对数据库的依赖及给数据库造成的压力。 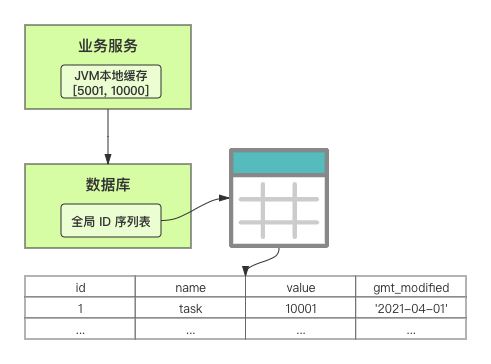 总结一下, 号段模式每次向全局 ID 序列表获取一批可以使用的 ID 号段,然后存入 JVM 本地缓存中。 其中,我们需要预申请 5000 个 ID 中的“5000”,我们称为 步长。当这批号段被消耗完了,我们再向全局 ID 序列表重新发起一次读写请求。当 5000 个 ID 被消耗完了之后,才会重新读写一次数据库。因此,读写数据库的频率从 1 减小到了 1/5000。 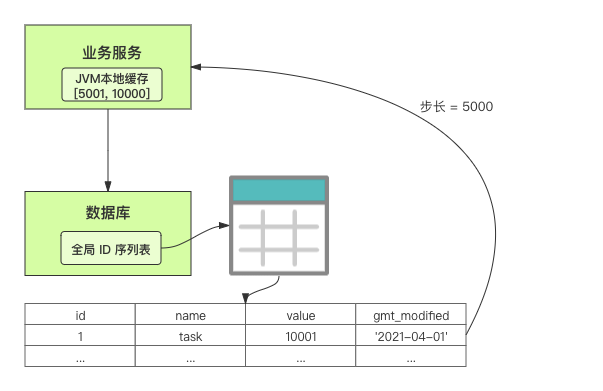 号段模式 不仅提升了数据库读写性能,还很方便我们做横向的线性扩展。 假设,我们部署 3 台客服工单服务,它们分别申请可用的[5001, 10000]、[10001, 15000]、[15001, 20000]号段。然后呢,全局 ID 序列表将该业务的自增 ID 可用值更新为 20001。多台客服工单服务之间凭借号段生成算法的原子性,保证每台服务上的可用号段不会重复,从而使得 ID 全局唯一。 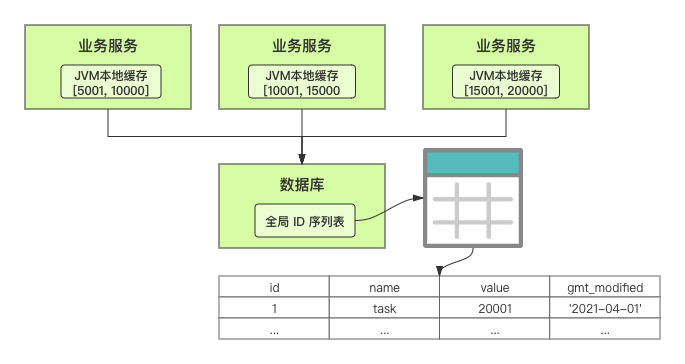 使用号段模式实现分布式 ID,有哪些常见问题?想一想,这个流程会不会存在什么潜在问题?事实上,会的。 服务重启,可用号段浪费我们遇到的第一个问题是,如果某台客服工单服务重启了,那么该号段就作废了。因此,我们需要 特别注意步长的配置,尽可能减少可用 ID 的浪费。 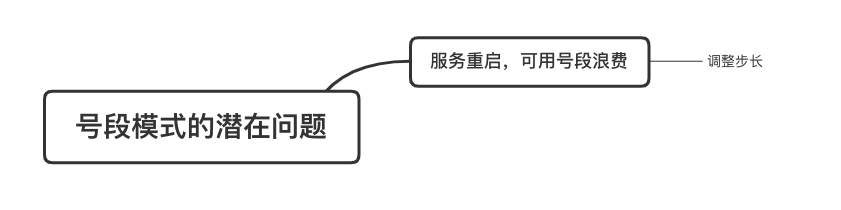 但是呢,减少步长的大小,间接的就会提升数据库的性能压力,因为数据库的读写数据库的频率是 1/步长。 因此,步长的配置需要一个折中的配置策略。我们可以用观测平时的业务峰值,和大促时的业务峰值,来动态配置步长。此外,由于重启导致的可用 ID 的浪费,也会造成 ID 不是连续的,不过,这对于大部分业务都是可接受的。 并发安全:多态服务同时获取 ID 区间段我们遇到的第二个问题是,如果是多台服务同时获取号段,可能会发生竞争问题。 其实呢,我们可以 使用悲观锁来解决。最容易实现的方案就是,用数据库自身的行锁。数据库行锁在数据处理过程中,将数据处于锁定状态,来保证数据访问的排他性。 如果考虑到数据库的悲观锁会阻塞等待,我们也可以考虑 给全局 ID 序列表加一个版本号,通过乐观锁的方式来实现。也就是说,每次更新都加上版本号,保证并发更新的正确性。 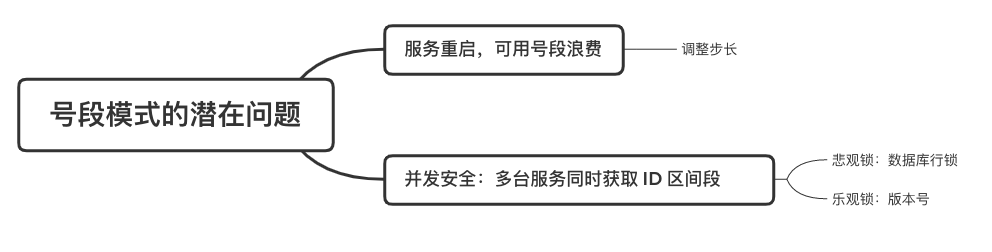 监控大盘的毛刺:线程阻塞等待我们遇到的第三个问题是,当服务消费完号段之后,向全局 ID 序列表重新发起读写请求时,在这个临界点可能会发生线程阻塞在数据库取回号段的等待,它带来的表象就是监控大盘上的偶尔会出现的毛刺。 对于这个问题,业界提出了  双号段缓存方案 的思路是,在号段快用完的时候,我们异步加载下一个可以使用的号段,保证 JVM 本地缓存中始终有可用的号段。因此,我们就不需要等到号段用完的时候才去更新号段,以此来避免性能波动。 事实上,双号段缓存方案中,服务内部的缓存区有两个号段:号段 A 和号段 B。当前号段 A 用到一定程度的时候,如果下一个号段 B 还未更新,则服务开启一个线程异步更新下一个号段 B。 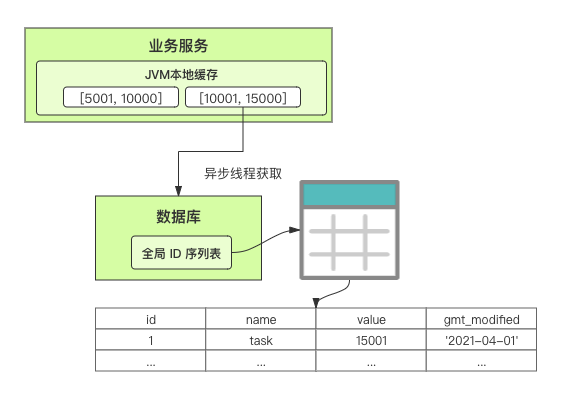 当前号段 A 全部消耗完之后,同时,下一个号段 B 准备好了,那么把缓存区中的号段 A 与号段 B 切换,也就是说,当前可用号段 A 变成了号段 B,如此反复循环切换。 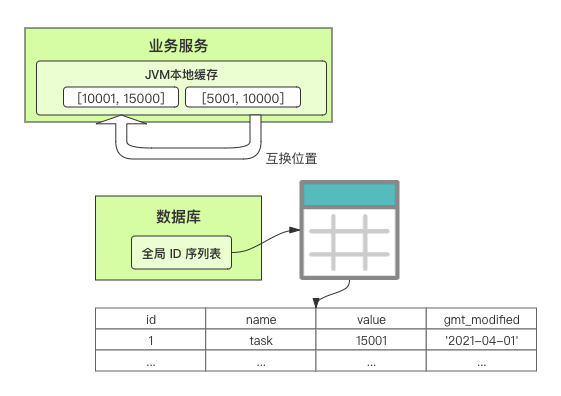 单点故障我们遇到的第四个问题是,数据库只有一个实例时,会存在单点故障。也就是说,如果数据库不可用,则获取号段不可用。因此,我们还要支持多数据库实例。 这个时候,我们还需要引入两个新的概念, 外步长和内步长:
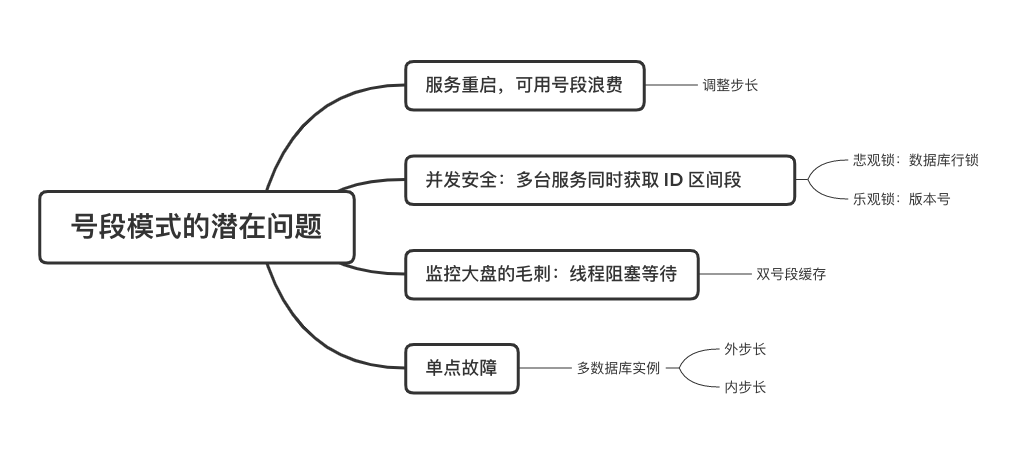 这里,有一个公式来计算新值。这个新值,是用来计算号段的生成区间。 我举一个案例。假设有两个数据库实例,我们设置外步长是 1000,内步长也是 1000。客服工单服务向数据库 1 申请可用的[1, 1000]号段。 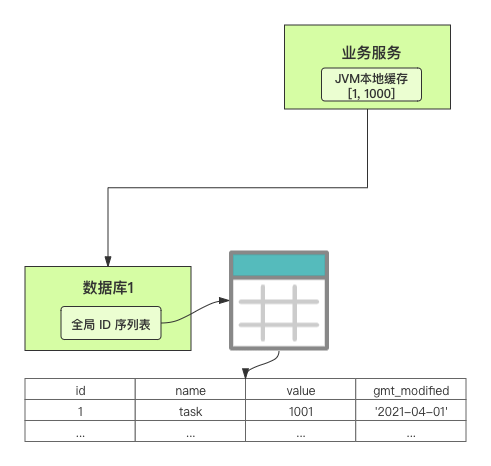 当 1000 个 ID 被消耗完了之后,再重新读写一次数据库,正好此时路由到了数据库 2,然后呢,数据库 2 分配可用的[1001, 2000]号段,然后根据计算公式把自己的值更新为 2001。 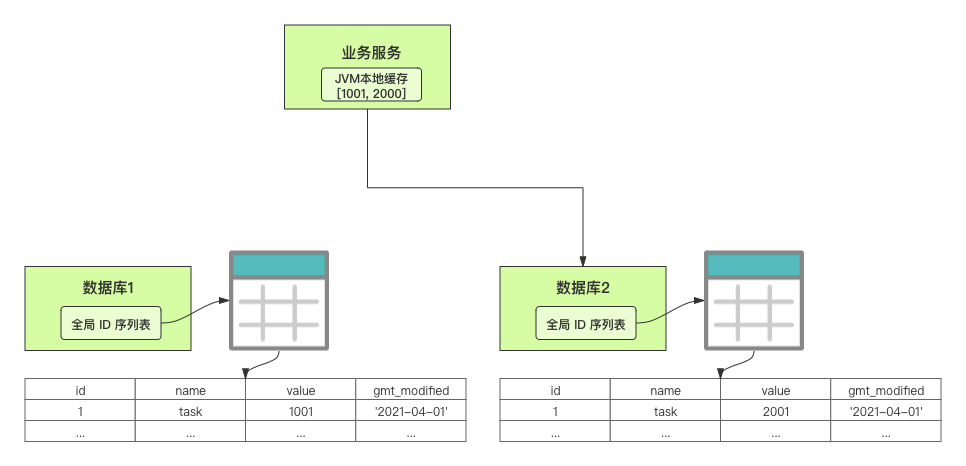 总结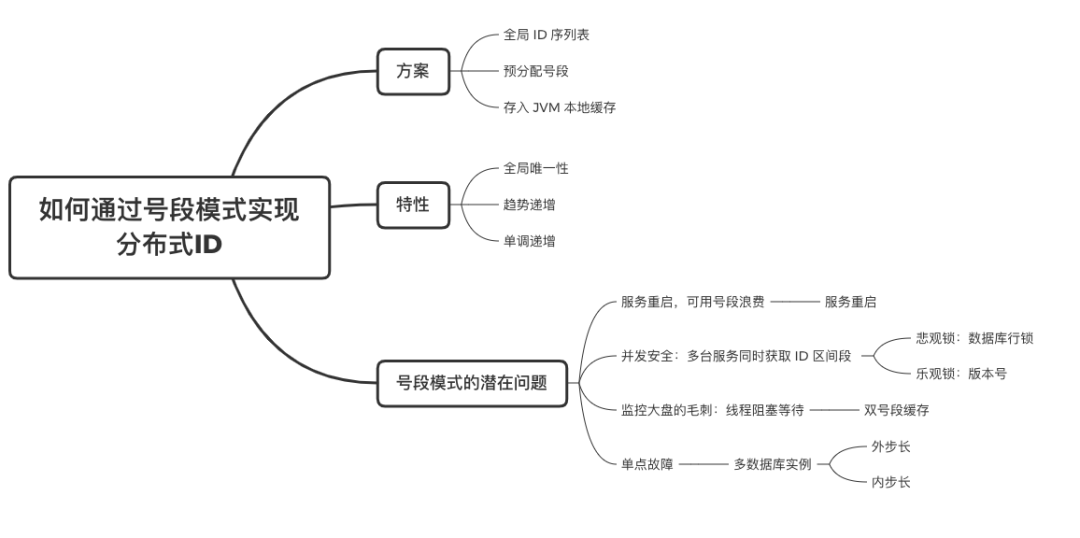 我们围绕如何通过号段模式实现分布式 ID 进行了讨论。号段模式满足全局唯一性、趋势递增、单调递增三个要求。 首先,我们需要了解号段模式,它通过每次向全局 ID 序列表获取一批可以使用的号段,然后存入 JVM 本地缓存中使用,当这批号段被消耗完了,再向全局 ID 序列表重新发起一次读写请求。 在具体实现中,使用号段模式还有 4 个潜在问题:
该文章在 2024/10/23 9:57:19 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886


