在过去的实践中,我们通常通过爬取HTML网页来解析并提取所需数据,然而这只是一种方法。另一种更为直接的方式是通过发送HTTP请求来获取数据。考虑到大多数常见服务商的数据都是通过HTTP接口封装的,因此我们今天的讨论主题是如何通过调用接口来获取所需数据。
目前来看,大多数的http接口数据都采用restful风格,通常使用JSON格式来发送和接收数据。对于那些对此不太了解的零基础学者,建议先学习相关知识点。在本章学习过程中,我们将主要以腾讯云开发者社区作为主要平台,练习爬取接口数据。
接口爬取
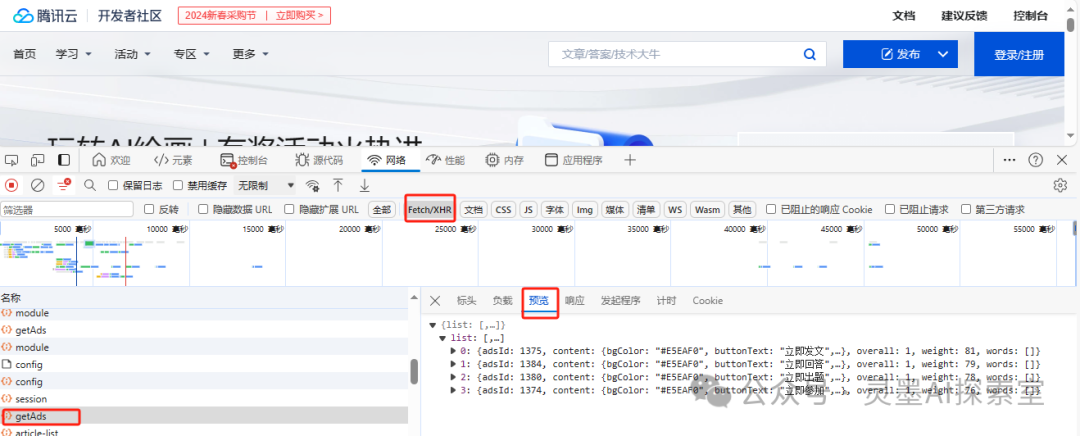
接口爬取并不复杂,首先需要在浏览器中打开腾讯云社区的网页,然后按下F12打开控制台,接着浏览控制台中的请求数据接口,有些接口可能一眼难以识别,但通常可以跳过细致查看,因为在开发过程中,最关键的是能从名称中直观理解其作用,大型公司通常设计得相当清晰。我们首先尝试爬取主页的活动数据。
 image
image
我们可以选择使用XHR来单独查看请求,这样就能排除掉页面、js、css等无关的请求,逐个检查接口,找到我们需要的内容。这个特定接口就是我们必须记住的,其他的都是多余的。
便利工具
在这里,我们想向大家介绍一个非常实用的开发爬虫工具,它就是https://curlconverter.com/
我是通过偶然的机会发现了这个工具的,它的确大大提升了我的爬虫效率。通常情况下,当我们找到了需要爬取的接口时,我们需要编写Python代码来发起请求,可能还要处理各种请求头和cookie,这一过程会消耗大量时间。而这个工具则帮助我们省去了这些繁琐的步骤,使得整个过程变得更加高效。
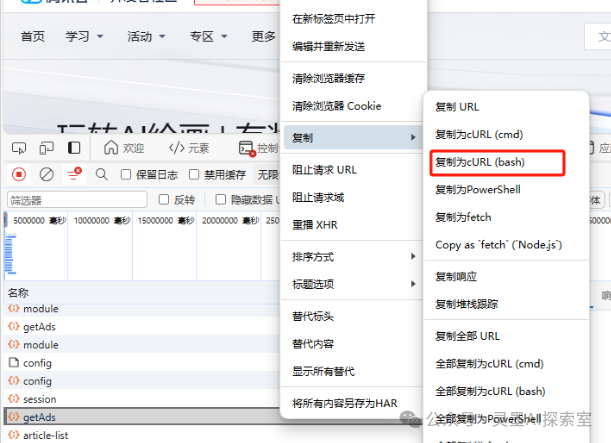
首先,我们在后台查找到目标请求,然后通过右键点击复制该请求。以Edge浏览器为例,具体操作如下所示:
 image
image
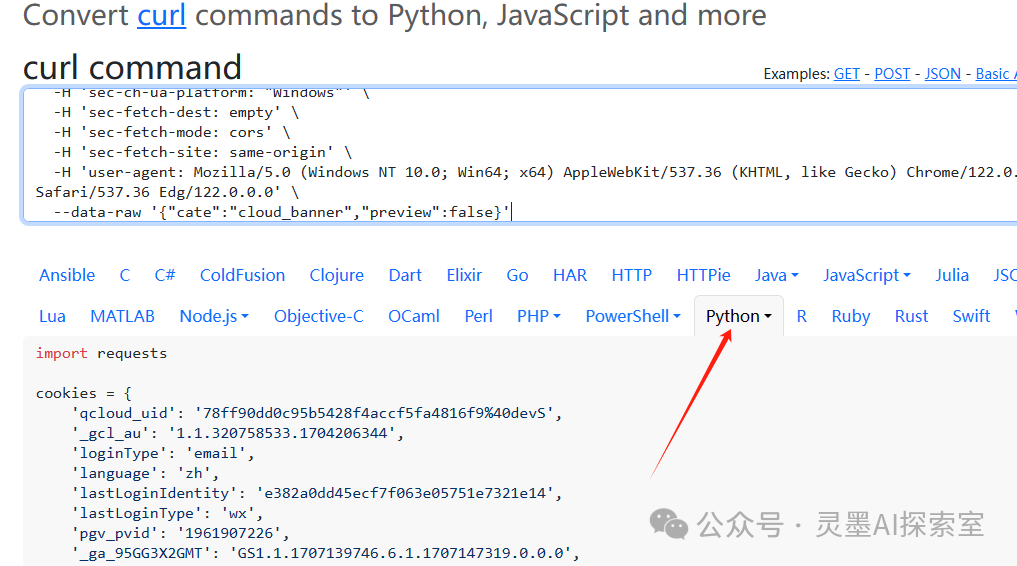
在将内容复制后,我们可以直接前往这个在线工具网站,将其粘贴进去,从而生成相应的Python代码。这里以使用requests库为例进行演示。当你浏览该网站时,你可以选择你喜欢的任何编程语言进行相应代码的生成。
 image
image
我们只需简单地将其复制粘贴到IDE中,然后便可直接运行代码。
社区首页
一旦我们掌握了这种方法,基本上就可以获取想要爬取的所有数据,只要避免频繁请求而被识别为机器人爬虫。让我们首先尝试爬取社区首页的文章,以了解今年哪些类别的文章备受关注。以下是示例代码:
import datetime
import requests
ad_list = []
article_list = []
article_total = 0
def get_article_list(pageNumber):
global article_total,article_list
## 这里不需要cookie也是可以的。
headers = {
'authority': 'cloud.tencent.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'content-type': 'application/json',
'cookie': 'qcloud_uid=3db7bb7a1663470df3290f692c4a7206; language=zh; lastLoginIdentity=e382a0dd45ecf7f063e05751e7321e14; _ga_6WSZ0YS5ZQ=GS1.1.1685003902.1.1.1685004114.0.0.0; loginType=email; _ga_7PG2H0XLX2=GS1.2.1705284469.2.1.1705284470.59.0.0; lastLoginType=email; _gcl_au=1.1.315225951.1705902067; _ga_95GG3X2GMT=GS1.1.1707206895.14.0.1707212112.0.0.0; _ga=GA1.2.100014169188; mfaRMId=0092627a989e3ef79957c2257ea910f8; qcloud_from=qcloud.google.seo-1709083904498; qcstats_seo_keywords=%E5%93%81%E7%89%8C%E8%AF%8D-%E5%93%81%E7%89%8C%E8%AF%8D-%E8%85%BE%E8%AE%AF%E4%BA%91; from_column=20421; cpskey=1f39dac98ac4cc96c6503bdb4f49994f; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22100014169188%22%2C%22first_id%22%3A%221878e0e485111b-0be585a75d9ef-7e57547d-2073600-1878e0e4852ec0%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_utm_medium%22%3A%22ocpc%22%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMTg3OGUwZTQ4NTExMWItMGJlNTg1YTc1ZDllZi03ZTU3NTQ3ZC0yMDczNjAwLTE4NzhlMGU0ODUyZWMwIiwiJGlkZW50aXR5X2xvZ2luX2lkIjoiMTAwMDE0MTY5MTg4In0%3D%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%24identity_login_id%22%2C%22value%22%3A%22100014169188%22%7D%2C%22%24device_id%22%3A%221878e0e485111b-0be585a75d9ef-7e57547d-2073600-1878e0e4852ec0%22%7D; qcmainCSRFToken=NSsz_8Bfx1S_; qcloud_visitId=3e799aa8be55222ade40e7ab9b8be875; intl=; _gat=1; trafficParams=***%24%3Btimestamp%3D1710467373372%3Bfrom_type%3Dserver%3Btrack%3Da7699f0f-3309-4c6b-9740-475f6c5f11ba%3B%24***',
'origin': 'https://cloud.tencent.com',
'referer': 'https://cloud.tencent.com/developer',
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Microsoft Edge";v="122"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',
}
json_data = {
'pageNumber': pageNumber,
'pageSize': 100,
'type': 'recommend', ## 文章是否被推荐到首页
}
response = requests.post(
'https://cloud.tencent.com/developer/api/home/article-list',
headers=headers,
json=json_data,
)
news_list = response.json()
for article in news_list['list']:
## 处理一下文章的类别
handle_tag(article)
## 可以自己解析首页的文章,只拿你想要的
article_list.append({
"article_title": article['title'],
"article_date": article['createTime'],
"article_summary": article['summary']
})
article_total = news_list['total']
fixed_time = datetime.datetime(2023, 1, 1)
timestamp = int(fixed_time.timestamp())
print(f'{article_list[-1]["article_date"]}和{timestamp}')
## 判断一下是否已经是最后一页
return 0 if article_list[-1]['article_date'] < timestamp else 1
def handle_tag(article):
# 遍历解析后的数据,统计每个tagName的数据量
for item in article['tags']:
tag_name = item["tagName"]
if tag_name in tag_counts:
tag_counts[tag_name] += 1
else:
tag_counts[tag_name] = 1
def get_top_10():
# 根据数据量对tagName进行排序
sorted_tag_counts = sorted(tag_counts.items(), key=lambda x: x[1], reverse=True)
# 取前10个tagName
top_10_tags = sorted_tag_counts[:10]
# 打印前10个tagName的数据量统计
for tag, count in top_10_tags:
print(f"{tag}: {count}")
page_num = 1
while True:
num = get_article_list(page_num)
page_num = page_num + 1
if num == 0:
break
get_top_10()
代码首先通过API获取文章列表数据,然后遍历每篇文章的标签信息,统计每个标签出现的次数,最后输出每个标签和其对应的数据量。这样可以帮助用户了解哪些标签在文章中出现频率较高。除了这些,我还额外处理轮播活动的数据,获取更全面的活动信息。
import datetime
import requests
ad_list = []
def get_ads():
global ad_list
headers = {
'authority': 'cloud.tencent.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'content-type': 'application/json',
'origin': 'https://cloud.tencent.com',
'referer': 'https://cloud.tencent.com/developer',
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Microsoft Edge";v="122"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',
}
json_data = {
'cate': 'cloud_banner',
'preview': False
}
response = requests.post('https://cloud.tencent.com/developer/api/common/getAds', headers=headers, json=json_data)
news_list = response.json()
ad_list = [{'pcTitle': item['content']['pcTitle'], 'url': item['content']['url']} for item in news_list['list']]
get_ads()
print(ad_list)
我的文章
如果我们希望对我们自己的文章进行分析和处理,首先需要进行登录。原本我打算尝试通过编写代码实现免登录,但是仔细研究后台 JavaScript 和登录验证后发现实现起来涉及的内容过多,对我们这样以学习为主的学者来说并不适合。
确保我已经登录的标识是通过 cookie 实现的。Cookie 在这里的作用是保持用户登录状态,使用户在不同页面之间保持登录状态。由于 HTTP 是无状态的,需要一种方法来保持会话连接,而这种方法就是使用 Cookie。对于请求来说,Cookie 就是一串字符串,服务器会自动解析它,无需我们手动管理。因此,我只需在网页登录后使用工具复制粘贴 Cookie 即可。尽管我花费了一整天,但仍未成功编写代码实现登录并获取 Cookie。因此,我们最好选择最简单的方法。
示例代码如下:
import requests
def get_my_article(page_num):
headers = {
'authority': 'cloud.tencent.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'content-type': 'application/json',
'cookie': '',# 这里需要复粘贴你自己的cookie。
'origin': 'https://cloud.tencent.com',
'referer': 'https://cloud.tencent.com/developer/creator/article',
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Microsoft Edge";v="122"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',
}
page_size = 20
json_data = {
'hostStatus': 0,
'sortType': 'create',
'page': page_num,
'pagesize': page_size,
}
response = requests.post(
'https://cloud.tencent.com/developer/api/creator/articleList',
headers=headers,
json=json_data,
)
news_list = response.json()
for article in news_list['list']:
# handle_tag(article)
# 这里我就不解析了,简单打印一下吧。
my_article_list.append({
"article_title": article['title'],
"article_date": article['createTime'],
"article_summary": article['summary']
})
article_total = news_list['total']
if page_num*page_size > article_total:
return 0
else:
return 1
在这个函数中,参数page_num代表着要获取的文章列表页数。请务必留意,请求头中的headers需要包含用户自行提供的Cookie信息,这样才能确保程序正常运行。您可以在这里获取到Cookie信息,只需将其复制粘贴即可。详见下图:
 image
image
总结
在过去的实践中,我们常常通过爬取HTML网页来解析和提取数据,因此今天我们讨论了如何通过调用接口来获取所需数据。本文通过示例代码展示了如何爬取社区首页的文章和活动数据,以及如何爬取自己的文章列表。通过这些实践,我们可以更好地理解和运用接口爬取技术。
该文章在 2024/3/27 8:59:04 编辑过






 400 186 1886
400 186 1886


