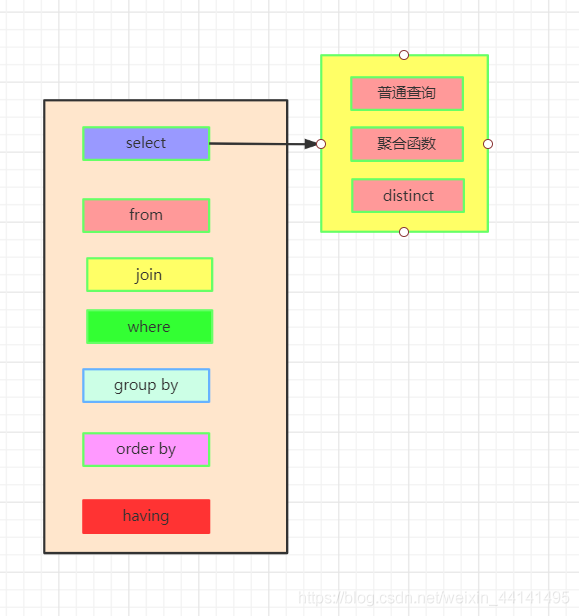
图解 SQL 的执行顺序,优雅
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
这是我们实际上SQL执行顺序:
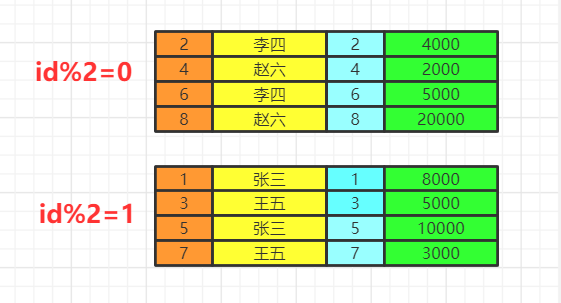
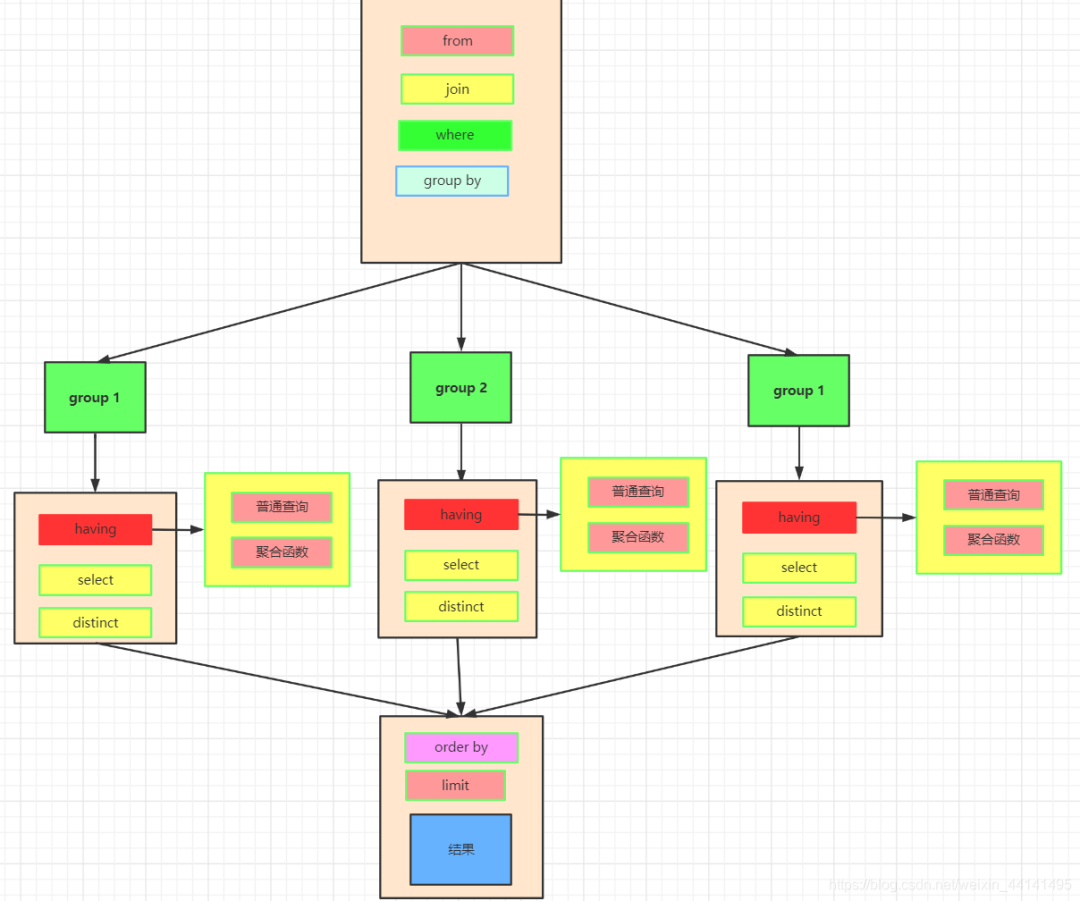 数据的关联过程数据库中的两张表 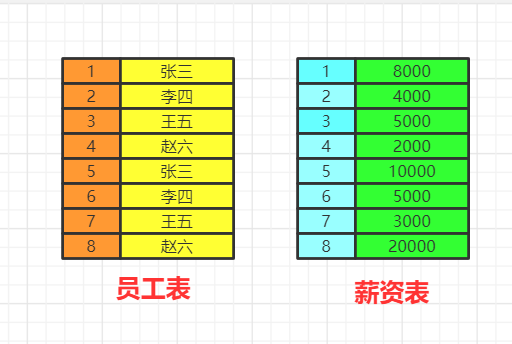 from&join&where用于确定我们要查询的表的范围,涉及哪些表。 选择一张表,然后用join连接 选择多张表,用where做关联条件 我们会得到满足关联条件的两张表的数据,不加关联条件会出现笛卡尔积。 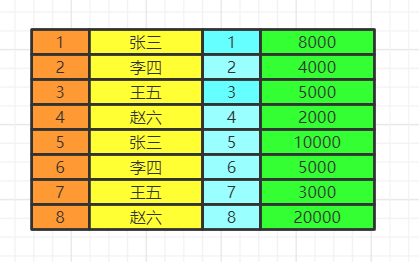 group by按照我们的分组条件,将数据进行分组,但是不会筛选数据。 比如我们按照即id的奇偶分组 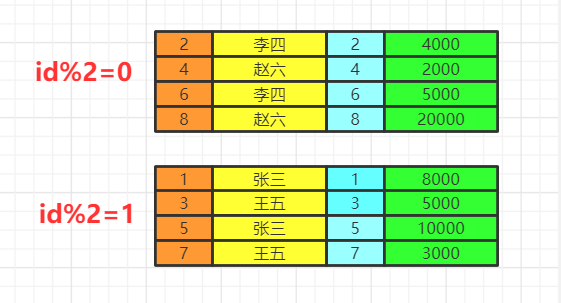 having&wherehaving中可以是普通条件的筛选,也能是聚合函数。而where只能是普通函数,一般情况下,有having可以不写where,把where的筛选放在having里,SQL语句看上去更丝滑。 使用where再group by先把不满足where条件的数据删除,再去分组 使用group by再having先分组再删除不满足having条件的数据,这两种方法有区别吗,几乎没有! 举个例子:
不同的是,having语法支持聚合函数,其实having的意思就是针对每组的条件进行筛选。我们之前看到了普通的筛选条件是不影响的,但是having还支持聚合函数,这是where无法实现的。 当前数据分组情况
执行having的筛选条件,可以使用聚合函数。筛选掉工资小于各组平均工资的 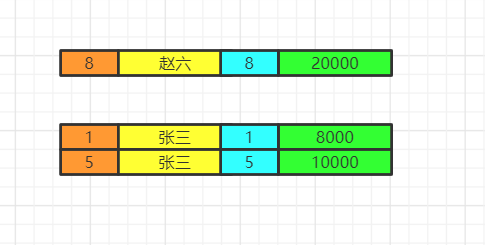 select分组结束之后,我们再执行select语句,因为聚合函数是依赖于分组的,聚合函数会单独新增一个查询出来的字段,这里用紫色表示,这里我们两个id重复了,我们就保留一个id,重复字段名需要指向来自哪张表,否则会出现唯一性问题。最后按照用户名去重。 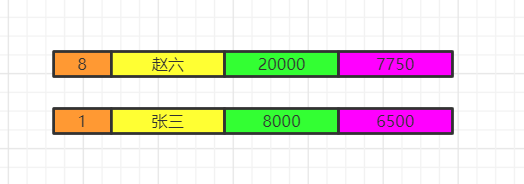 将各组having之后的数据再合并数据。 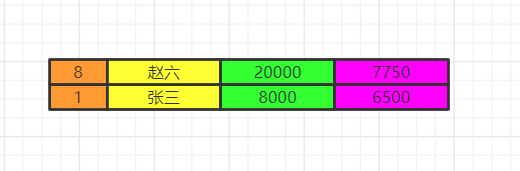 order by最后我们执行order by 将数据按照一定顺序排序,比如这里按照id排序。如果此时有limit那么查询到相应的我们需要的记录数时,就不继续往下查了。 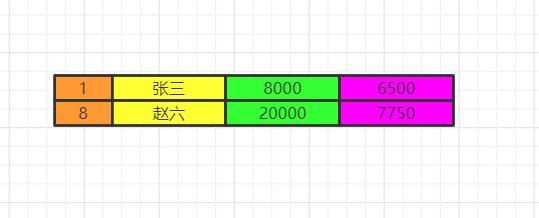 limit记住limit是最后查询的,为什么呢?假如我们要查询年级最小的三个数据,如果在排序之前就截取到3个数据。实际上查询出来的不是最小的三个数据而是前三个数据了,记住这一点。 我们如果limit 0,3窃取前三个数据再排序,实际上最少工资的是2000,3000,4000。你这里只能是4000,5000,8000了。 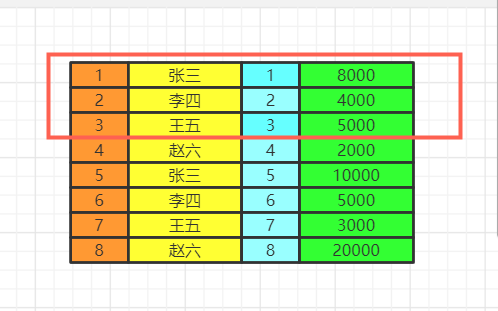 该文章在 2023/10/7 9:52:00 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886