为什么 PDF 导出中文会乱码?——从一个字符说起
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
如果你用过任何前端表格组件的 PDF 导出功能,大概率遇到过这个场景:表格里明明都是正常的中文,数据一丝不差,可一旦点击「导出 PDF」,打开文件一看——中文部分变成了方块、问号,或者干脆一片空白。 第一反应往往是:这是不是组件的 Bug? 但如果你换一台电脑再打开同一个 PDF,它可能又正常了。或者你把同一份数据换成纯英文,导出就完全没有问题。 这些现象指向同一个答案:这不是 Bug,而是 PDF 这种文件格式的「天性」决定的。 要理解这件事,我们需要从一个最基本的问题说起:浏览器和 PDF,对「字体」的理解完全不同。
网页和 PDF:两种完全不同的渲染哲学网页是怎么显示文字的当你在浏览器中打开一个网页,看到一行中文时,浏览器在幕后做的事情其实非常「将就」:
这个过程是实时的、动态的、借力的。浏览器从来不把字体打包在网页里(Web Font 是另一回事),它依赖的是用户电脑上已有的字体资源。 所以你在开发机上看到中文正常显示,并不是你的代码里做了什么特别的事情——那只是因为你的操作系统自带了中文字体。Windows 有微软雅黑和宋体,macOS 有苹方和华文,Linux 通常也装了文泉驿或思源黑体。 浏览器只是在"借用"这些已有的资源。 PDF 是怎么显示文字的PDF 的设计初衷就和网页完全不同。 PDF(Portable Document Format,便携式文档格式)是 Adobe 在 1993 年提出的,它的核心承诺只有一句话:
要兑现这个承诺,PDF 就不能像网页那样"借用"外部环境的东西。它必须是一个完全自足的文件——打开它所需要的一切信息,都必须打包在这个文件内部。 用一个比喻来说:
字体,就是这份"便当"里的餐具。如果你没有把餐具放进去,打开便当的人就得自己找餐具——能找到什么就用什么,找不到就只能用手抓。
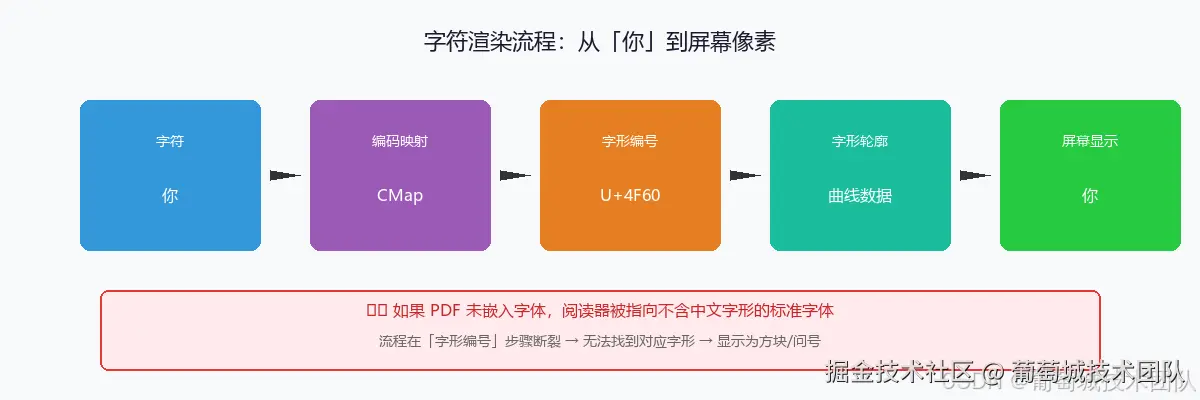
拆解 PDF 内部发生了什么让我们放大一个最小的场景,看看当 PDF 中出现一个字符「你」的时候,PDF 阅读器到底在做什么。 要在屏幕上画出「你」这个字,PDF 阅读器需要知道两件事: 第一,字符编码映射。 PDF 需要知道:文字中的「你」这个字符,对应字体文件中的哪一个「字形(Glyph)」。字体文件内部有成千上万个字形,每个字形有一个编号。这个映射关系叫做 CMap(Character Map)。 第二,字形轮廓数据。 找到对应的字形编号后,PDF 阅读器需要知道这个字的笔画长什么样。在字体文件中,每个字形都是一组数学描述——贝塞尔曲线、控制点、笔画粗细等等。阅读器根据这些数据,把字"画"出来。 所以整个过程是这样的: 字符「你」 → 查编码映射表 → 找到字形编号 → 读取字形轮廓数据 → 渲染成像素显示在屏幕上 如果 PDF 文件中嵌入了字体,这两步信息都在文件内部,阅读器可以顺利地画出正确的字形。 如果没有嵌入字体呢?事情就变得棘手了。 导出引擎在生成 PDF 时,必须在文件中写入一个「字体引用」——告诉阅读器应该用什么字体来渲染文字。当没有嵌入字体时,引擎通常会回退到 PDF 内置的 14 种标准字体之一(比如 Helvetica)。问题是,这些标准字体只包含拉丁字母、数字和基本标点,它们的字形表里根本没有中文字符。 于是 PDF 阅读器读到的指令就变成了:「请用 Helvetica 这个字体,画出"你"这个字」。阅读器翻开 Helvetica 的字形表一查——没有「你」。它没有其他字形数据可用,只能显示为空白、方块或者问号。 一个常见的误解是:「我的电脑装了宋体,为什么 PDF 阅读器不去用它?」 原因在于,PDF 文件中告诉阅读器的是「用 Helvetica 画」,而不是「去系统里找宋体」。阅读器忠实地执行文件中的指令,不会自作主张去系统字体库里搜索替代品。浏览器能显示中文,是因为它直接调用了操作系统的字体接口;PDF 能不能显示中文,完全取决于文件内部有没有对应的字体数据。这是两条独立的路径,互不影响。 为什么偏偏中文容易出问题你可能会注意到:英文文档导出 PDF 很少遇到乱码,为什么一到中文就出问题? 答案藏在 PDF 的历史规范里。 PDF 格式在诞生时,内建了 14 种「标准字体」(Standard 14 Fonts),包括我们熟悉的 Helvetica、Times-Roman、Courier 等。这些字体有几个特点:
中文的情况完全不同:
这个量级决定了中文字体不可能像拉丁字体那样被"默认内置"。没有任何 PDF 阅读器会预装几万个汉字的字形数据作为"标准兜底"。所以,中文字体必须由文档的创建者主动提供——也就是嵌入到 PDF 文件中。 这就是中文 PDF 乱码的根本原因:PDF 的标准字体不覆盖中文字符,而你又没有把中文字体嵌入进去,阅读器自然无法正确渲染。 解决方案:注册字体到底在做什么理解了上面的原理,解决方案就水到渠成了。 "注册字体"的本质所谓的"注册字体",本质操作只有一件事:
这个操作并不神秘。你提供的字体文件(通常是 这样,PDF 就变成了一份"自带餐具的便当",在任何设备上都能正确显示。 子集化:为什么不用把整个字体塞进去一个自然的担忧是:一个中文字体文件动辄几 MB 甚至十几 MB,嵌入之后 PDF 文件岂不是会变得巨大? 这就要提到一个关键技术:字体子集化(Font Subsetting)。 子集化的逻辑很简单:你文档中用了哪些字符,就只嵌入那些字符的字形数据。 举个例子,你的表格中出现了 500 个不同的汉字。导出引擎在嵌入字体时,不会把整个字体文件的 20,000+ 个字形全部放进去,而是只提取这 500 个字的字形数据,打包成一个"迷你字体"嵌入 PDF。 效果非常显著:
可以看到,即使你加载了一个 8 MB 的完整字体文件,最终 PDF 中实际增加的体积可能只有几十到几百 KB,完全在可接受的范围内。 大多数支持字体嵌入的 PDF 导出引擎(包括 SpreadJS 的导出模块)都会自动执行子集化,你不需要手动处理。
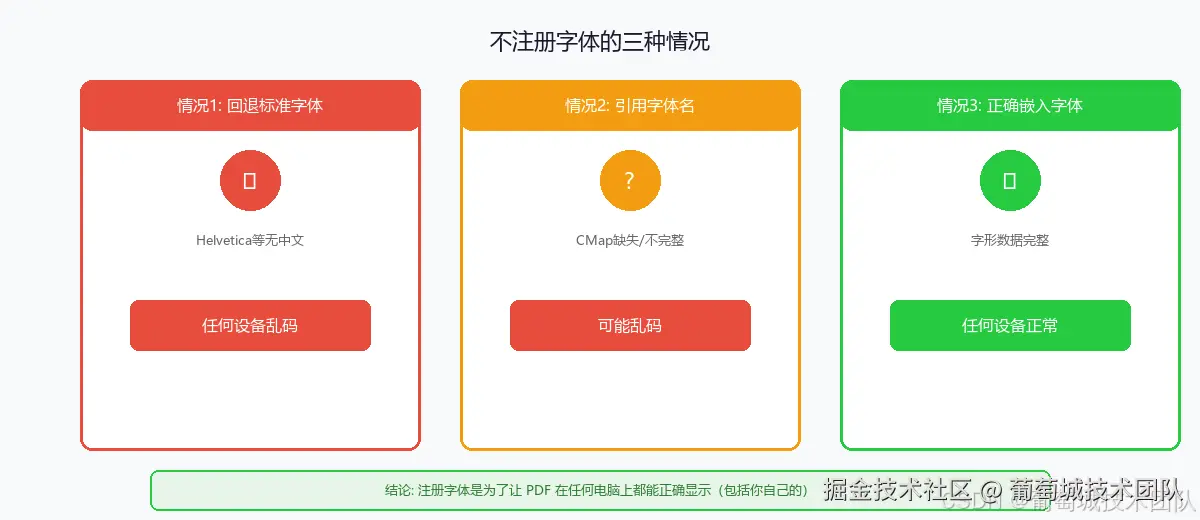
如果不注册字体,会怎样有人可能会问:如果我不注册字体,PDF 阅读器总能想办法显示出来吧? 答案是:大概率不行。 我们来分析几种情况: 第一种:导出引擎回退到 PDF 标准字体。 这是最常见的情况。未注册字体时,导出引擎默认使用 Helvetica 等标准字体。这些字体里没有中文字形,PDF 阅读器拿到的指令是「用 Helvetica 画"你"字」——画不出来,直接显示为空白、方块或问号。这种情况在任何电脑上打开都是乱码,跟用户系统装了什么字体无关。 第二种:导出引擎恰好引用了某个中文字体的名称。 有些引擎在未嵌入字体时,可能会根据 CSS 中的 第三种:某些 PDF 阅读器会尝试智能替换。 部分阅读器(如 Adobe Acrobat)在检测到缺少字形时,会尝试用本地系统字体做"降级替换"。这种情况下,内容可能以替代字体勉强显示出来。但这取决于阅读器的具体实现和用户的操作,不是所有阅读器都支持,替换后的排版效果也无法保证。 所以结论是:不注册字体导出的 PDF,即使在你自己的电脑上,大概率也是乱码。 浏览器能正常显示中文,是因为浏览器直接调用了操作系统提供的字体服务;而 PDF 是独立的自足文件,它的渲染能力完全取决于文件内部携带的字体数据。这两者走的是完全不同的路径。 这也引出了一个关键认知:注册字体不是为了让 PDF 在"别人"的电脑上能看,而是为了让 PDF 在"任何"电脑上都能看——包括你自己的。
在 SpreadJS 中如何注册字体SpreadJS 作为领先的类 Excel 表格控件,也支持 PDF 导出的能力,所以也会存在上述的字体问题,那么在理解了原理之后,解决这个问题其实很简单。 SpreadJS 的 PDF 导出模块提供了 基本用法如下: 总结回顾一下全文的核心逻辑:
一张速查表:
最后多说几句回到文章开头的那个场景:表格在浏览器里显示得完完整整,导出 PDF 就乱码了。现在你知道了——这不是谁的代码写得有问题,而是两种完全不同的技术体系在底层逻辑上的差异。 浏览器的世界是「借用」的哲学:操作系统有什么字体就用什么,实时渲染,用完即走。它的灵活性很高,但代价是显示效果依赖环境——换一台电脑,结果可能不同。 PDF 的世界是「自足」的哲学:所有渲染所需的信息都要打包带走。它的代价是创建者需要多做一步(嵌入字体),但换来的是一个承诺——不管谁打开、在哪里打开、用什么设备打开,你看到的内容和作者设计的完全一样。 这个承诺听起来理所当然,实现起来却需要每一个细节都被妥善处理。字体,就是那个容易被忽略的细节。 理解了这层原因之后,「注册字体」就不再是一个莫名其妙的额外步骤,而是一个自然且必要的动作——就像寄快递时确认包裹里放了说明书一样,多花几秒钟,换来的是收件人拿到手就能用。 希望这篇文章能帮你少踩一个坑。如果下次遇到 PDF 相关的问题,记住这个底层思路:PDF 的一切显示问题,都可以从「文件内部到底携带了什么」这个角度去排查。 转自https://juejin.cn/post/7646302254307622964 该文章在 2026/6/3 14:49:02 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886