Python为什么不解决四舍五入(round)的“bug”?
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
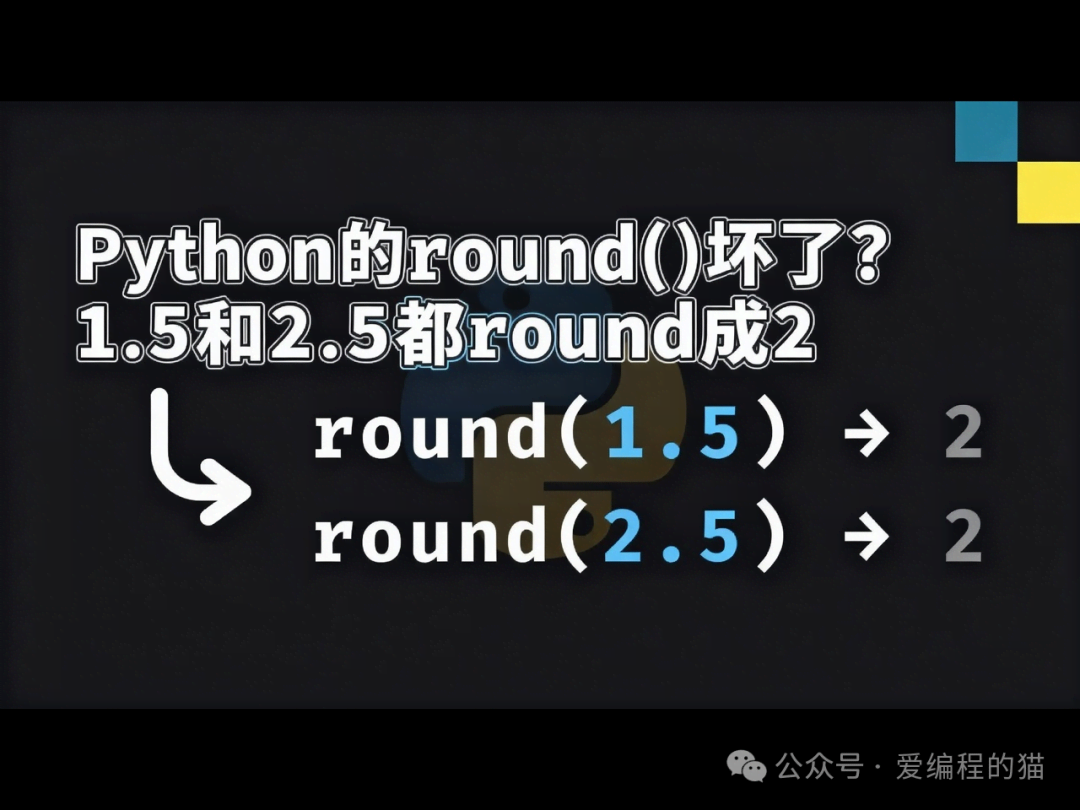
用Python做四舍五入时,肯定会遇到过这种 “诡异” 情况:
甚至 其实这根本不是bug!无数开发者踩坑的背后,是二进制浮点数的 “天然特性” 和round()的特殊设计逻辑。今天就从底层原理到实际用法,一次性讲清round()的所有 “门道”。 先看现象:那些让人困惑的round()结果先一起围观几个典型案例,看看你是否也曾被这些结果劝退:
为什么1.25保留1位小数不是1.3?为什么1.45 的真实值不是1.45?要解答这些问题,得先从计算机存储数字的底层逻辑说起。 核心原因 1:二进制浮点数的 “天生缺陷”我们习惯用十进制(0-9)表示数字,但计算机底层只认识二进制(0 和 1),所有十进制浮点数都会被转换成二进制后存储。而问题的关键的是:不是所有十进制小数都能被二进制精确表示。 十进制与二进制的转换规则一个十进制有理数 n/d(既约分数)能被 B 进制有限表示的条件是:d 的所有素因子都能整除 B。
像 0.2(1/5)、0.3(3/10)、1.45(29/20)这类分数,分母含 2 和 5 以外的素因子,转成二进制后是无限循环小数。但计算机存储容量有限,只能截取有限位数保留,这就导致了存储误差。 比如 1.45 转成二进制后是无限循环序列,Python 的 float 类型(64 位浮点数,53 位尾数)会截取并存储为近似值,其十进制等效值就是 1.44999999999999995559—— 你以为在对 1.45 做四舍五入,实际是在对一个有误差的近似值操作,结果自然不符合预期。 关键结论在调用 round () 之前,很多十进制浮点数已经因为 “十进制→二进制” 的转换产生了微小误差。round () 的 “反常” 结果,往往是这种误差的延续,而非函数本身的问题。 核心原因 2:round () 的设计逻辑 —— 不是 “四舍五入”,是 “精度对齐 + 银行家舍入”除了存储误差,round () 的核心设计逻辑也和我们认知的 “四舍五入” 不同,这是另一个重要 “坑点”。 第一层逻辑:round () 是 “对齐到指定精度的倍数”round () 的完整语法是
这就能解释为什么 第二层逻辑:中点情况的 “银行家舍入”当 x 刚好在两个目标倍数的正中间(如 1.25 在 1.2 和 1.3 中间、2.5 在 2 和 3 中间),round () 会采用 “银行家舍入(Banker’s Rounding)” 规则,而非传统的 “逢五进一”。 银行家舍入规则当数值处于中点时,舍入到最近的偶数(最终结果的末位为偶数),目的是避免大规模计算时的系统性偏差。 看几个典型例子:
为什么需要银行家舍入?传统 “逢五进一” 会导致结果整体偏大:比如计算 0.5、1.5、2.5、3.5 的平均值,传统舍入结果是 1、2、3、4(平均值 2.5),而银行家舍入结果是 0、2、2、4(平均值 2.0),后者更均衡,无系统性偏差,这在金融、统计等对精度敏感的领域至关重要。 解决方案:不同场景的正确用法了解底层逻辑后,我们可以根据场景选择合适的方式,避免踩坑。 场景 1:日常展示 / 普通报表直接使用 round () 即可。银行家舍入在统计学上更合理,且日常场景对精度要求不高,无需额外处理。 场景 2:需要传统 “四舍五入”(如价格计算、游戏数值)自定义函数实现 “远离 0 的四舍五入”,支持正负数值和任意小数位:
场景3:金融/高精度计算(如记账、转账)使用Python的 decimal 模块,支持十进制精确运算和自定义舍入规则,彻底避免二进制存储误差:
场景 4:特殊取整需求速查表:常见 round () 结果汇总(建议收藏)Python 的 round () 从来不是 bug,而是 “二进制浮点数存储特性” 和 “银行家舍入设计” 共同作用的结果:
掌握这些原理后,你不仅能轻松应对 round () 的各种 “反常” 结果,还能根据实际场景选择最合适的取整方式 —— 这才是真正理解了 Python 的设计思想,而非单纯记用法~ 阅读原文:https://mp.weixin.qq.com/s/udtd6b3WcUsXXepvEcCw1g 该文章在 2025/12/26 12:07:18 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886