索引数据结构原理
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
索引就相当于一本字典的目录。 在数据库中,索引就是一种能够快速查找的数据结构,能够加快SQL执行速度的。 字典里面,一页一页翻找的这种形式,就是全表扫描,通过目录查数据就是索引查询。 所以执行SQL时,执行走索引比全表扫描的速度快。 数据库用哪种数据结构做索引比较好? 常见的数据结构有 哈希表、二叉排序树、平衡二叉树、红黑树、B树、B+树。 哈希表:用唯一的key去查对应的value啊,时间复杂度O(1),它很快,但是没办法做范围查询,也没办法排序。 二叉排序树:左节点小于根,右节点大于根,中序遍历它就是有序的,所以它可以做排序,也可以范围查询,但是二叉排序树顺序插入的情况下,它会退化为链表,性能就会很差。 为了解决退化成链表,使用平衡二叉树 平衡二叉树:插入节点使用旋转操作,让这个二叉树去保持平衡对吧?左右子树的高度差不大于1。平衡二叉树呢,能够避免极端情况下退化为链表,但是由于平衡二叉树它追求绝对完美的平衡,会导致频繁的左旋右旋去保持平衡。但应用于数据库中,当插入删除的时候频繁旋转会带来大量的磁盘IO,降低性能,那再升级一下变成红黑树。 红黑树:也是一种自平衡的二叉排序树,通过插入删除数据的时候去变色、旋转,让树保持平衡。 但是红黑二叉树它不追求绝对的平衡,只要大致平衡就可以了,这就大大的降低了插入删除需要的这个旋转操作,应用到数据库中就减少磁盘I/O。但是,红黑二叉树它是一种二叉树,一个节点只能有两个孩子,存储大量数据的时候树高就会很高,那排序树的查找性能和树高是直接相关的,你存大量数据的时候,红黑树的查找性能其实没那么好,要多次的磁盘I/O。所以,红黑树其实适合存储少量数据的内存操作 那它是一个二叉树,高度太高,那有没有一种方法?可以用B树。 B树:多路平衡排序树,一个节点可以有n个孩子,数据量大的情况,树高也不会像红黑树那么高。但是B树的节点呢,又存数据又存索引值,就导致了B树的一个节点存不了多少索引,树高就会变得比较高。而且B树做范围查询的时候,它需要回溯整个树结构,效率比较低,会产生很多的随机I/O,所以B树也不行,得上B+树。 B+树:也是这种多路平衡排序树,而且B+树的非叶子节点只存索引值,它不存数据。 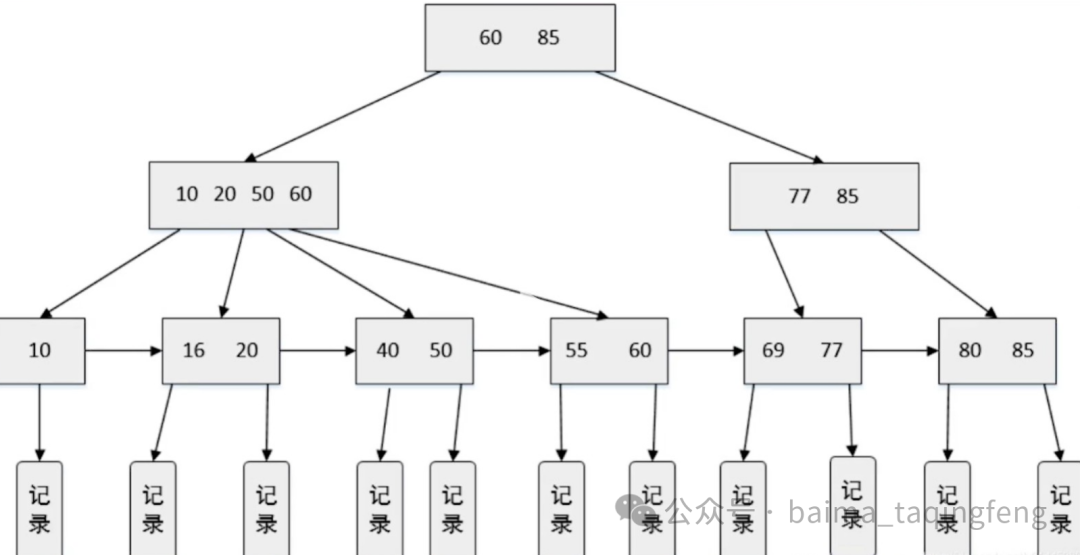 那不存数据,B+树单个节点能存的索引值就变多了,树的高度是更低的,查询性能更好了。 B+树的数据只存在于最下面的叶子节点,且叶子节点由双向链表去连接。范围查询,只需要遍历链表就可以了,不用回溯树结构,所以性能是更好的。 所以呢,像MySQL这种数据库就会选用B+树来保存索引。 那B+树具体是怎么存储数据的呢? MySQL索引从存储结构上划分主要有两种:聚集索引、非聚集索引 聚集索引:索引值和数据一块存, 非聚集索引:索引值和数据分开存。 举个例子啊,像主键索引,它就是聚集索引,非叶子节点它都是索引值,然后叶子节点呢,保存全部索引值和对应的行数据啊,这里索引值就是ID, 这种索引呢,就是联合索引。所谓联合索引呢,就是针对表中的多个字段去创建索引。呃,举个例子啊,你对姓名、年龄两个字段去建立联合索引,那索引列就是姓名和年龄,索引树的叶子节点就会存储这两个字段的值,还挂了ID。 那如果我去执行什么select id,姓名,年龄,where姓名等于段多少多少多少多少,那就可以走联合索引,然后呢,直接就能查到id、姓名、年龄,就能避免回表查询,提升性能。所以减少回表查询的方式之一呢就是创建联合索引,然后尽可能的去避免使用select*,因为select*查到的所有的列数据,它就会很容易触发回表。 最左前缀匹配法则。 联合索引因为有多个索引列,所以排序的时候会根据索引列的顺序排。 查找的时候会根据索引列的顺序,从左到右依次匹配。 比如说建立联合索引abc,MySQL底层建B+树的时候会先根据 a去排序,再根据b去排序,再根据c排序。所以查询的时候得先从 a开始查,如果a不存在,那b、c就是乱序的。 同样的,如果a、b不存在,c也一定是乱序的,它无法跳过前面的索引列去匹配,所以必须从左到右依次使用索引列去匹配。 例如: 建立联合索引abc, 查询条件a =1and b=2 ---会走索引 查询条件 b=2 and c=3 ---不会走索引 查询条件 a=1 and c=3 ---部分走索引 可以这样理解: 把联合索引当做n级菜单,比如这里你设置了abc三个联合索引,a就是一级菜单,b就是一级菜单下的二级菜单,c就是二级菜单下的三级菜单,因此当你查询条件直接从b开始的时候,找不到b的一级菜单,必定会触发全局扫描,就为了找b的上级菜单,所以此时就不会走索引 索引,并不是越多越好,而且所以会降低增删改的性能,因为你增删改的数据呢,同时要更新对应的索引,所以索引肯定不是越多越好,也不是万能的。 那怎么加索引比较好呢? 数据量比较大的,查询频繁的就适合加索引,经常where,group by,order by的列呢,适合建索引。 增删改频繁的就不适合加索引了。 对于区分度比较高的列也比较适合做索引,像身份证号这种的。 但是,性别这种区分度很低的就不适合加索引。 注意一张表的索引不能太多,最多不要超过五个,不然会大大降低插入和删除的效率。 阅读原文:原文链接 该文章在 2025/12/15 9:02:54 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886


