在后端面试中,“MySQL 的 IN 子句最多能放多少个值” 是道高频题。很多人会背 “1000 个” 的错误答案,或只知道max_allowed_packet参数,却答不出底层原理和性能优化方案 —— 这恰恰是面试官考察的核心。
今天我们就彻底搞懂这道题:先打破认知误区,再深挖底层逻辑,最后给出可直接落地的实战方案,让你不仅能答对面试题,还能解决生产环境的真实痛点。
一、先破:3 个常见认知误区
在深入分析前,先纠正 3 个流传最广的错误认知:
误区 1:MySQL 官方规定 IN 最多放 1000 个值
这是最常见的误解!MySQL 官方文档从未明确限制 IN 列表的值数量,“1000 个” 只是部分版本的 “软阈值”(优化器对 IN 列表的处理逻辑切换点),而非硬性限制。
误区 2:IN 的底层是 “排序 + 二分查找”
很多文章会说 “IN 列表会先排序,再对每行做二分查找”,这是对 MySQL 优化器的误解。实际处理逻辑取决于主表是否有索引,与二分查找无关(后文详细拆解)。
误区 3:调大max_allowed_packet就能无限加值
调大该参数确实能突破 SQL 长度限制,但会引发更严重的性能问题(内存溢出、索引失效),属于 “治标不治本” 的错误做法。
二、底层原理:IN 子句到底是怎么执行的?
要搞懂 IN 的限制,先明白它的底层执行逻辑 —— 核心取决于主表是否有可用索引,两种场景完全不同:
场景 1:主表有索引(主键 / 普通索引,最常见)
当查询字段有索引时,MySQL 会将 IN 列表解析为「索引范围扫描条件」,而非逐行匹配:
- 例:
select * from user where id in (1,3,5)(id 为主键) - 执行逻辑:MySQL 会先对 IN 列表去重,再按索引顺序组织成 “id=1 OR id=3 OR id=5” 的等价条件,直接扫描索引中对应的位置(索引本身有序,无需额外排序)。
- 时间复杂度:O (K),K 是匹配到的结果数,与 IN 列表长度无关 —— 哪怕 IN 有 500 个值,只要匹配结果只有 10 条,执行效率依然很高。
场景 2:主表无索引(全表扫描)
当查询字段无索引时,MySQL 会将 IN 列表转成「哈希表」,而非排序后二分查找:
- 执行逻辑:先把 IN 列表的所有值加载到内存构建哈希表(去重 + O (1) 查找),再全表扫描主表,每行数据去哈希表中判断是否存在。
- 时间复杂度:O (T),T 是主表总行数 —— 哪怕 IN 只有 100 个值,若主表有 1000 万行,依然会全表扫描,效率极低。
总结核心逻辑:IN 的执行效率,关键看是否能走索引,而非 IN 列表的长度。
三、真正的限制:3 重枷锁决定 IN 的 “安全阈值”
虽然 MySQL 无官方数量限制,但受 3 重实际约束,生产环境中需控制 IN 列表长度:
1. 硬限制:SQL 语句长度(max_allowed_packet)
这是最直接的限制,max_allowed_packet参数控制单条 SQL 的最大字节数(默认 4MB/16MB,可通过show variables like 'max_allowed_packet'查看)。
- 限制逻辑:IN 列表的每个值都会占用字节(int 型约 4 字节,字符串 = 值长度 + 2 字节),当 SQL 总长度超过阈值,会直接报错:
ERROR 1153 (08S01): Got a packet bigger than 'max_allowed_packet' bytes
- 示例:若 IN 列表全是 int 型值,4MB 理论上能放约 100 万个值,但实际中 SQL 还包含表名、字段名等,根本达不到 —— 且会先触发性能问题。
2. 内存限制:解析与存储开销
MySQL 执行时会将 IN 列表加载到内存,构建哈希表或范围条件:
- 若 IN 列表值过多(如 10 万个):内存占用暴增,可能导致 MySQL OOM,或抢占其他查询的内存资源;
- 解析耗时:MySQL 需对 IN 列表去重、校验,值越多 CPU 消耗越大,甚至拖垮整个实例。
3. 性能限制:索引失效的 “隐形杀手”
这是生产中最该关注的限制,也是面试高频延伸点:
- 少量值(≤500):优化器优先走索引,查询毫秒级;
- 大量值(>1000):优化器会判断 “走索引的范围扫描成本高于全表扫描”,直接放弃索引 —— 大表查询瞬间从 “毫秒级” 变成 “秒级”;
- 额外损耗:IN 列表越长,执行计划生成时间越长,进一步拖慢查询。
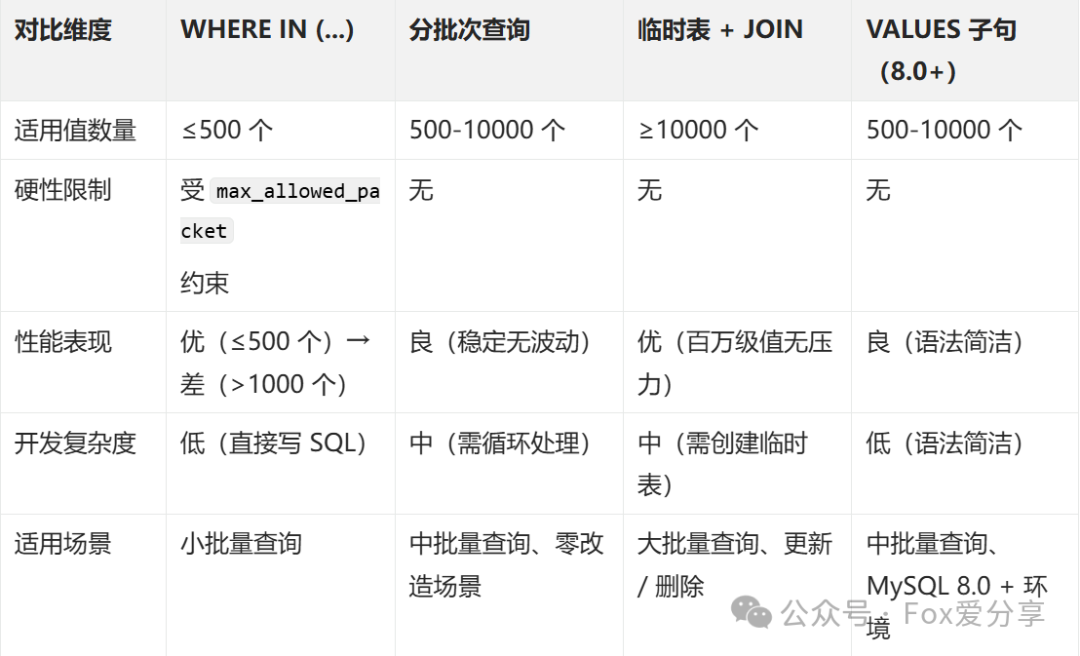
四、实战方案:IN 列表超限时的 3 种最优解
当业务需匹配大量值(如批量查询 1 万个用户 ID),直接用大 IN 列表是下策,推荐 3 种更优方案:
方案 1:分批次查询(最常用,零改造)
把大列表拆成多个小批次(每批 500 个值),循环查询后合并结果。
List<Long> allIds = new ArrayList<>(); List<User> result = new ArrayList<>();for (int i = 0; i < allIds.size(); i += 500) { int end = Math.min(i + 500, allIds.size()); List<Long> batchIds = allIds.subList(i, end); List<User> batchResult = userMapper.selectByIds(batchIds); result.addAll(batchResult);}
select * from user where id in (1,2,...,500); select * from user where id in (501,...,1000);
- 优点:简单易实现,不依赖额外组件,性能稳定;
- 注意:读操作可并行,写操作需控制批次间隔(避免压库),应用层需处理结果去重。
方案 2:临时表 + JOIN(超大量值首选,性能最优)
把所有值插入临时表,用 JOIN 替代 IN,避免长 SQL 和索引失效。
CREATE TEMPORARY TABLE temp_ids (id bigint PRIMARY KEY) ENGINE=InnoDB;
INSERT INTO temp_ids (id) VALUES (1),(2),...,(10000);
SELECT u.* FROM user u INNER JOIN temp_ids t ON u.id = t.id;
DROP TEMPORARY TABLE IF EXISTS temp_ids;
- 优点:支持 10 万 + 值,JOIN 走索引,性能比大 IN 列表高一个量级;
- 适用场景:批量查询、批量更新 / 删除(如批量删除 1 万个无效用户)。
方案 3:VALUES 子句替代(MySQL 8.0+,无需临时表)
用VALUES构建虚拟表,再 JOIN 查询,语法更简洁,本质和临时表一致。
SELECT u.* FROM user uJOIN ( VALUES (1), (2), ..., (10000) ) AS t(id) ON u.id = t.id;
- 优点:无需手动创建临时表,语法简洁,执行效率接近临时表方案;
- 注意:
VALUES子句行数仍受max_allowed_packet限制,但比直接写 IN 列表支持的数量更多。
五、核心对比表:3 种方案怎么选?
六、面试加分:3 个延伸知识点
- IN vs EXISTS:大数据量怎么选?当 IN 列表值多且子查询数据量小时,
EXISTS更优(如select * from user u where exists (select 1 from t where t.id = u.id))。原因:EXISTS 是 “半连接”,只判断 “存在性”,不加载所有值到内存,避免内存溢出。 max_allowed_packet调整建议若确实需要调大,建议 “临时调整 + 用完恢复”:
SET GLOBAL max_allowed_packet = 16 * 1024 * 1024; -- 临时调为16MB
长期调太大风险:增加 SQL 注入危害,占用更多内存资源。
- 分库分表场景的特殊处理若数据分库分表(如按 ID 哈希分片),大 IN 列表会导致 “全库全表扫描”,此时需:
- 按分片规则拆分 ID 列表,路由到对应分片查询;
- 用分布式临时表(如 ShardingSphere 的临时表功能),再聚合结果。
七、总结:面试标准答案
最后,我们把所有知识点浓缩成面试能直接说的标准答案:
“MySQL 的 IN 子句没有官方规定的数量上限,真正限制来自 3 点:max_allowed_packet的 SQL 长度限制、内存解析开销、以及索引失效的性能风险。
实践中,我会把 IN 列表的安全阈值控制在 500 个以内;超过 500 个用分批次查询;超过 1 万个则用临时表 + JOIN 方案 —— 这不是因为触发了配置限制,而是为了避免索引失效和性能下降。
底层逻辑上,IN 子句有索引时走范围扫描,无索引时转哈希表查找,并非排序 + 二分查找;优化的核心是利用索引和避免大列表解析开销。”
这样的回答,既纠正了常见误区,又覆盖了原理、限制、方案,面试官一定会认可你的专业度。
阅读原文:原文链接
该文章在 2025/12/15 9:02:45 编辑过






 400 186 1886
400 186 1886